IncuVision 検出モジュール
画像認識 / モジュール
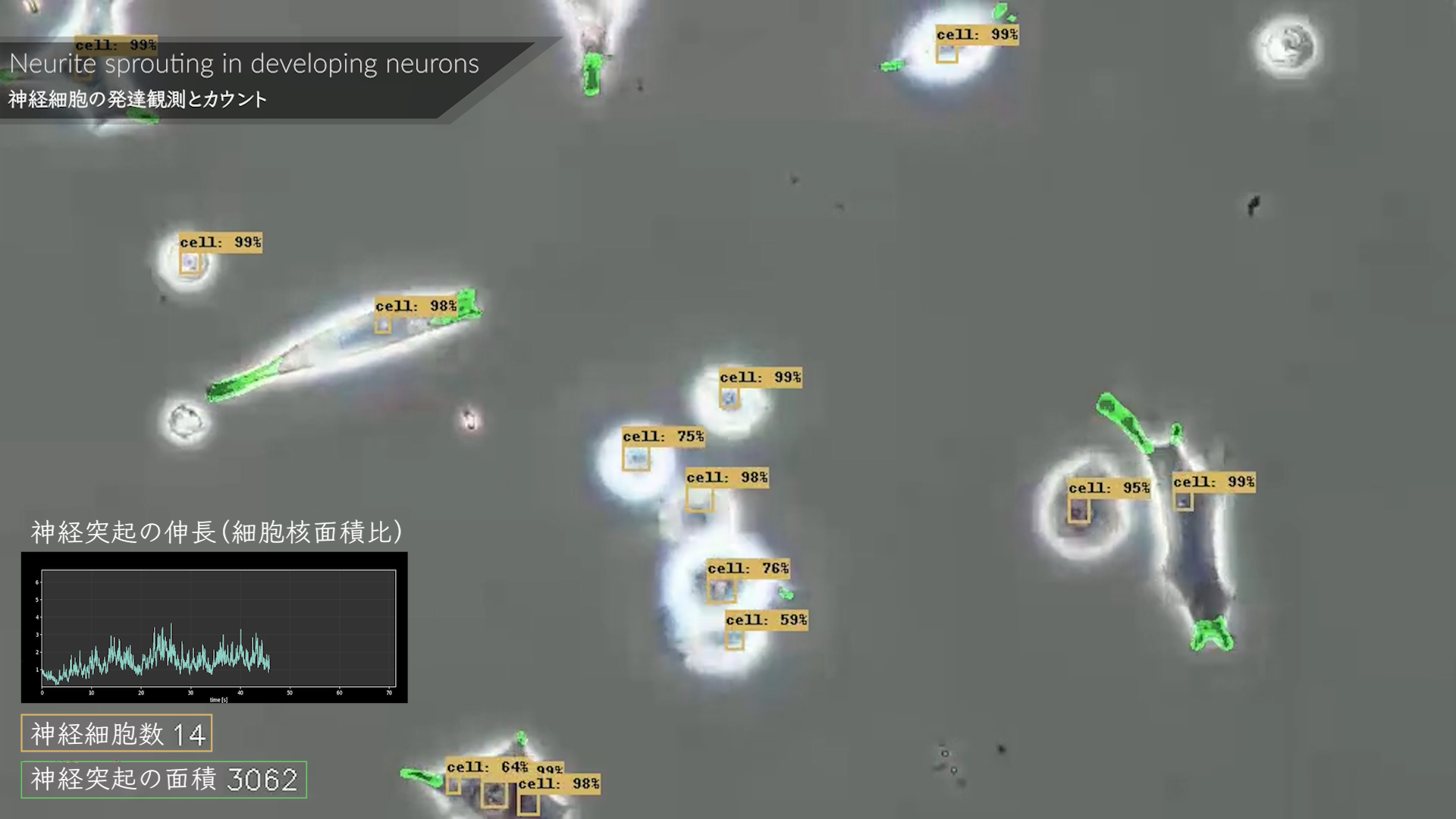
■ モジュール概要
画像内にある物体を検出するモジュールです。
■ 特徴
・少量の学習データのみで、高精度を実現。
・密に配置された非常に小さな検出物にも対応。
・検出結果は、CADファイルやSHAPEファイルでの出力も可能。
■ 応用例
・医療分野 : 腫瘍検出、細胞検出
・測量分野 : 道路付属物の検出
・点検分野 : 損傷箇所検出、異物検出
・建築分野 : 在庫カウントの自動化
・製造業 : 製造図面の解析
