Unsupervised Segmentation

Francis Hamilton

目次
Introduction:
Unsupervised training is an inherently difficult problem with negligible precedent. Even though it is considered the future of “AI” by big leagues such as Yoshio Bengio [1] and Yann Lecun, it is currently a difficult topic exacerbated further when dealing with segmentation. The success of modern deep learning algorithms heavily rely on supervision signals and without this supervisory signal there is no feedback on how well the algorithm is doing and thus no way to correct it.
Annotation is an expensive and time consuming process especially in dense pixel segmentation. In this research blog the goal would be to explore options, frameworks and algorithms which would allow segmentation to be done without manual pixel wise labels. An ideal solution to the problem would be that it includes the following properties:
- Discernible and fairly straight forward to grasp
- Trained from scratch (i.e does not used pretrained models from imagenet)
- Can be extended into a semi supervised setting
The dataset chosen to explore unsupervised segmentation is the Spacenet dataset. The reason is that it is open-sourced and contains a large amount of samples which would be needed for unsupervised training. Firstly, the available literature will be explored and discussed following this a direction will be taken and investigated for its efficacy. Finally some thoughts and final remarks will be presented.
Available Literature:
As mentioned above there is little precedent for unsupervised segmentation using deep learning. In general unsupervised and semi-supervised techniques tend to focus on first performing representational learning which is fully unsupervised followed by some form of clustering in the embedded space in the former and fine-tuning on the down stream task in the latter. While this is an excellent research direction there are many pit falls such as the representation learnt might not be suited for the downstream task. Self supervised is definitely an interesting avenue to purse however to date most algorithms are only shown through toy example or specific domain examples, generality is often an issue. As such only unsupervised segmentation literature will be presented.
An interesting non-deep learning approach [6] first does contour detection via multi scale local brightness, color, and texture cues to form a powerful globalization framework using spectral clustering. They then link this contour detector with a generic grouping algorithm. They use normalized cuts from spectral theory to form regions from the contour detection and subsequently group from there. In [4] they form an unsupervised architecture by concatenating two U-net models together. The intermediate representation is the segmentation. They incorporate a soft version of the normalized cut loss so as to have some sort of consistency and smoothness in the segmentation layer. They use CRFs to perform post processing. In [3] they implement an expectation maximization like algorithm whereby features are first extracted by a CNN then each pixel’s embedding are grouped with a superpixel refinement strategy. Grouping of the superpixels is done via hyperparameters and the features from the CNN. Like EM ist follows a label assignment and then an update to the features weights. Both [4] and [3] operate on the BSD500 dataset. In [4] they even compared their results to [6] and show that it only performs equally and in [3] they do not compare but visually it seems to perform the same if not worse.
An interesting paper [5] from NeurIPS uses the idea of scene composure to perform segmentation. They implement a fairly complex GAN architecture in which a segmenter network is trained to segment parts of an image in which a generator then fills the masked part. The discriminator is then trained to of course distinguish real from fake. An interesting point is how they ensure the segmenter network does not produce blank masks by enforcing that the generators output image must contain the noise information used to generate it, similar to infoGAN. It can take a while to work through the paper as the architecture is fairly complex yet the idea is a very promising direction as it allows it to work in an agnostic manner by theoretically being able to segment very different objects. It was shown to work on two relatively simple datasets however of course any GAN training is difficult. From the NeurIPS reproducibility challenge 2 papers [2][8] attempted to reproduce the results in a different deep learning framework. They pointed out several issues which were rectified with the original authors but they were unable to reproduce their results.
In [7] they propose a straight forward approach to unsupervised classification and segmentation. It is based on maximising the mutual information between two samples. They prove it first via classification and then extend it to segmentation. If there is a data pair which contains the same object the goal would be to learn a function which preserves what is in common between the two while discarding instance-specific details. The former can be achieved by maximising the mutual information between the outputs of the function. While the latter can be achieved by using a neural network with a small output capacity such as classes. Without a bottleneck the former can be achieved by just setting the function to the identity as this would be the maximum of the mutual information between the two samples. Mutual information expands to I(z, z^’) = H(z) − H(z|z^’). So maximising the mutual information function is a trade off between minimizing the conditional entropy term, H(z|z^’), and maximizing the entropy term H(z). The smallest value of the conditional entropy term is obtained when the cluster assignments are exactly predictable from each other [7]. The reader is referred to the paper and its supplementary material for more information as to why this avoids degenerate solutions.
Chosen Direction:
Out of the available literature explored the approach which stands out as not only interesting but also feasibly promising is the approach in the paper [7] Invariant Information Clustering for Unsupervised Image Classification and Segmentation. It satisfies the criteria listed in the Introduction and it can be extended into the semi-supervised setting fairly easily. The training pipeline consists of data pairs which are formed using the original image and a transformed version. The batch of data pairs are fed through the network with shared weights to output a softmax over a predefined number of classes. The outputs are fed into the objective function and backprograted through the network. Segmentation is essentially per pixel classification and thus in order to compare the outputs of the input data pairs output must be transformed back into the original input space so as to preserve spatial consistency.
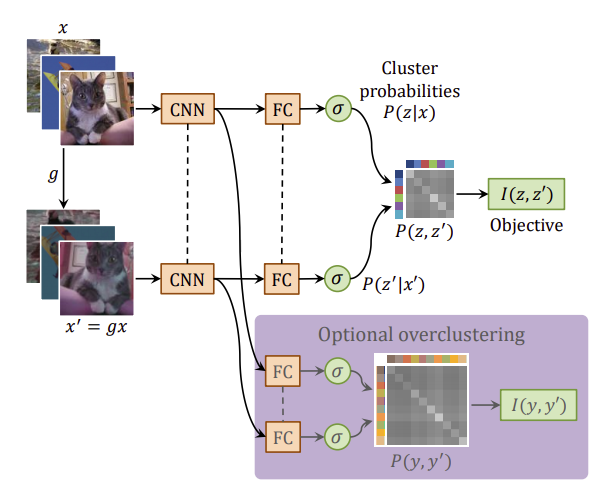
Overall training pipeline [7]
For example, in the unsupervised setting we would ideally like to segment buildings, roads and vegetation into three classes. However, in order to enable the network to learn a rich set of features it must have the capacity to separate the image into more classes such as buildings, trees, roads, cars, lakes etc. and so another output head is added which has a greater capacity which is referred to as overclustering.
Objective Function Explained:
The mutual information function between two random variables is given as:
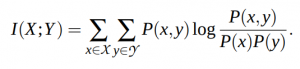
Since the last layer of the model is a softmax, the output Φ(x) is a distribution of a discrete random variable, z, over C classes:
![]()
The goal is to maximize the mutual information between sample pairs in a batch.
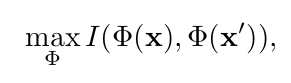
So after marginalization over batch, the joint probability distribution is given a the C × C matrix:
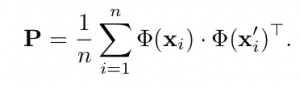
Plugging in this equation into the mutual information function results with the following objective function to maximise:
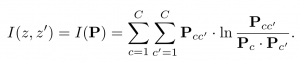
In order to extend this to segmentation there are a few more tricks needed such as reverting the transformation in the softmax output so as to keep spatial consistency. Please read the author’s paper and supplementary section for more information and look at their code implementation of the loss function [7].
The model:
The model is a standard VGG net style architecture, it is shown below:
- 1 x conv @ 64 with kernal = 3 and dilation = 1
- 1 x conv @ 128 with kernal = 3 and dilation = 1
- 1 x MaxPool 2D
- 2 x conv @ 256 with kernal = 3 and dilation = 2
- 2 x conv @ 512 with kernal = 3 and dilation = 2
- (Main Head) bilinear upsample, 1 x conv @ 512 -> 3 with kernal = 1
- (Over-clustering Head) bilinear upsample, 1 x conv @ 512 -> 24 with kernal = 1
As you can see the different heads take the encoding, upsample it to the original image resolution and reduce the channels, via 1×1 convolutions, to the desired number of classes to separate into.
Results:
The SpaceNet dataset consists of a large corpus of multi-spectral pan-sharpened satellite images but only the annotations are provided through challenges and so it is not possible to have access to both the building and road annotations at the same time. Thus the v2 building segmentation challenge is chosen specifically the Las Vagas area. The data is preprocessed to only include the RGB and IR channels for simplicity. The number of training samples with resolution 650×650 after post-processing is ~2300 and the number of test samples is ~700.
The main head (3 class output) would ideally output the three main classes being buildings, roads, and vegetation which then need to be matched to the ground truth with a one to one matching in order to calculate the accuracy performance. However, since only the building mask is available, it must be a many to one mapping. I.e building->building and roads&vegetation->not building. The same would go for the over-clustering head (24 class output) which will most likely contain multiple classes that represent the building ground truth class. This matching can be done manually by looking at the outputs but this would be time consuming so a many to one matching algorithm is used based on only 50 ground annotated examples.
The accuracy of the main head is ~79% whereas the over-clustering head is ~82%. As a comparison the model trained in a supervised fashion with 10% of the available data reaches ~90%. Below are some non-cherry picked outputs:
Top, left to right : RGB Input, Main Head Class Output, Over-Clustering Class Output
Bottom, left to right : Building Groundtruth, Main Head Matched Output, Over-Clustering Matched Output




Final Remarks:
I thought I would end this blog post with some final remarks about what I observed whilst implementing and testing different ideas.
– The loss function tends to more base separating classes based on colours. This coincides with the author’s findings whereby they incorporate two additional sobel edge pre-processed channels as inputs to the model. However, like the author’s findings this only seemed to improve the classification part of the paper and not the segmentation. It is most likely due to the different types of datasets used. For example, satellite images contain significantly more edges than say the STL-10 classification dataset. Out of curiosity I decided to pre-process the images with ZCA whitening as this decorrelates the pixels and forces the model to learn higher level distinguishing features, which is a common approach to unsupervised reconstruction such as auto-encoders. However, this actually made the performance worse which supports the notion of it learning to distinguish mainly between colours and not semantic objects in the scene.
– Following the idea of unsupervised reconstruction, I drew inspiration from the W-Net paper in which they concatenate another model to take the pixel-wise class encoding outputs and try to reconstruct the original image. The idea is that it forces the model to learn semantic object classes because it has to use the class map to fill in the “textures” in order to make it similar to the input image. Additionally I also included the soft normalized cut loss to force the model to learn class boundaries that better match the input image better. Including these losses did not hinder the performance of the model however, what can be noticed in the class encoded output is that a number of the classes appear to be a scattered within the main object classes. Not including the soft normalized cut loss causes the encoding to be less spatial consistent. This is in line with the W-Net paper in which they have to use CRFs and hierarchical grouping algorithms to produce consistent class encodings. An approach not tried in this blog post would be to include an additional loss which is based on the MSE between adjacent pixel’s class encodings. This would force the encoding to trade off between spatial consistent class encoding and grouping semantically similar objects through the mutual information loss or reconstruction loss.
– The W-Net paper and the ReDo paper are both based on a similar idea of scene composition, meaning a scene should be able to be separate in non-overlapping regions representing different objects. The difference between the two is the ReDO takes on an adversarial approach to take the object classes to “reproduce” the input. This allows the network to be less susceptible to the same object in different colour and texture forms. However, the major draw back apart from the mode collapse caused from the adversarial training is the segmenter network part which can struggle to initially produce semantically consistent outputs. As was mentioned in the introduction they use a few tricks to help guide the network but the training still remains extremely difficult especially with more complex datasets. An interesting avenue to pursue would be incorporating the mutual information loss at the output of the segmenter network part which could help to reduce the initial mode collapses.
References:
[1] https://www.ibm.com/watson/advantage-reports/future-of-artificial-intelligence/yoshua-bengio.html
[2] https://openreview.net/pdf?id=Bye09vnGpB
[3] Unsupervised image segmentation by backpropagation, Kanezaki, Asako
[4] W-net: A deep model for fully unsupervised image segmentation, Xia, Xide and Kulis, Brian
[5] Unsupervised object segmentation by redrawing, Chen, Micka and Arti`eres, Thierry and Denoyer, Ludovic
[6] Contour detection and hierarchical image segmentation, Arbelaez, Pablo and Maire, Michael and Fowlkes, Charless and Malik, Jitendra
[7] Invariant information clustering for unsupervised image classification and segmentation, Ji, Xu and Henriques, Jaao F and Vedaldi, Andrea
[8] Reproducibility Challenge@ NeurIPS 2019: Unsupervised Object Segmentation by Redrawing, Chmielewski-Anders, Adrian M and Steinweg, Mats and Straathof, Bas T
