Reinforcement Learning Research

Kevin Mandich
目次
Motivation
Reinforcement learning (RL) is a field of machine learning experiencing rapid change. At Incubit, part of our time is spent keeping up to date with the latest research so that we can deliver the best possible AI solutions to our customers. RL applications are not yet as prevalent as other areas of machine learning. However, the skills acquired while solving these problems are not only invaluable to have as an AI engineer, but also overlap heavily with these other areas.
We chose to recreate some of the recent results produced for Atari games, both because it is fascinating and technically challenging, and because open-source simulations are available. The results shown are only for Space Invaders, but the agent trained on this game also performs well on other Atari games.
Deep Q Network
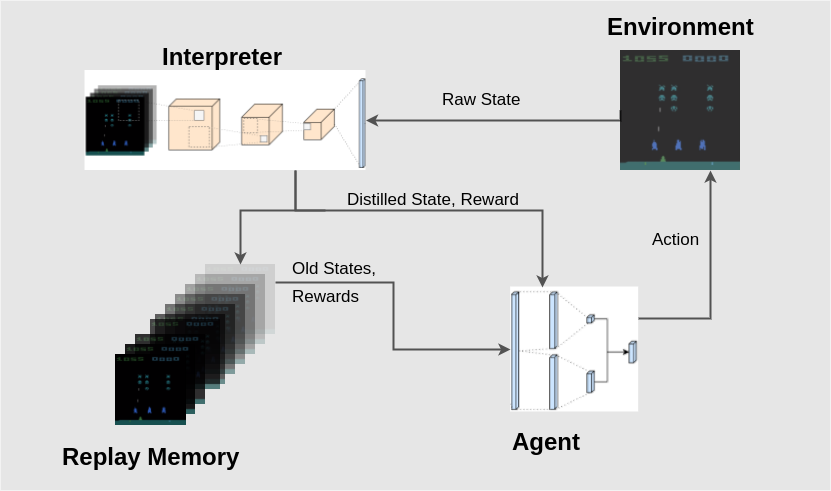
The agent used is based upon a deep Q network architecture. This approach utilizes several powerful methods which allow the agent to choose an action given a raw image:
- Convolutional filtering to create a vector representation of features present in an image
- Combination of consecutive frames
- An intelligent replay mechanism which utilizes important memories to accelerate training
- A value iteration method (Q-learning) to map states to future rewards
- Separate determination of value and advantage within the network
- Use of separate networks to choose an action and to generate target Q values for that action
Architecture
In general, a Q value is a function of the value at a specific state and the advantage to be gained by following each of the possible actions. To obtain a state representation, we have to reduce the dimensionality of the input data. Each input is a set of 4 frames of size 210 x 160 pixels with 3 color channels. With 256 values per pixel, this gives us a state space of 10 ^ 971004. We make this problem tractable through the use of a 4-layer convolutional neural network, which reduces this input space to a vector of size 512, a much more manageable number.
Multiple frames are utilized because it is generally not possible to determine the velocity of moving objects from a single frame. See two consecutive frames below:

By running multiple frames through the network, we can obtain a state representation not only of the current frame, but also of the velocity and acceleration of objects within the frame.
Here is a representation of the networks used to generate actions from a batch of consecutive frames:

The output of the last convolutional layer is fully-connected to a vector of size 512. This is split down the middle, and each resulting vector of size 256 is multiplied by a weight matrix to obtain the value and advantage functions. These are combined to obtain the final Q-value vector of length 6 for each of the actions. The action taken by the agent corresponds to the maximum Q-value in this output vector.
The second Target network is introduced for training stability. For each training step, the Main network generates the action to choose, and the Target network generates the target Q value for that action. The Main network is trained every step by minimizing the loss between generated and target Q values, and the Target network is updated with the network weights of the Main network every 500 steps.
Experience Replay
An experience buffer along with a prioritized replay scheme was used to accelerate training. The buffer consists of a maximum of 100,000 individual game frames, along with the action taken and the reward realized at that frame. During a network training step, a batch of replay examples is sampled from the buffer corresponding to a priority value assigned to each entry.
This value is a function of the difference between the Q values predicted by the network at time t-1 and the Q values predicted at time t. This is a measure of how “surprising” the transition is to the network. More surprising transitions are more likely to be chosen during the network training step.
Exploration
Exploration was achieved by using a simple random strategy: choose a random action with probability e. The value e was reduced from 1.0 to 0.025 linearly over 100,000 frames. Maintaining this minimum exploration helps to prevent the agent from settling on a sub-optimal policy. For Space Invaders, it is also useful for learning correct behavior near the end of a stage, where there is oftentimes only one alien ship left and it moves quickly. In this scenario, it is useful to learn both correct and incorrect behaviors (e.g. shooting and killing the alien vs. hesitating and letting it touch down).
Training
Training steps were performed every 8 time steps on a batch of 32 frames sampled from the priority replay buffer. The target network was fully updated with the weights from the primary network every 500 time steps. Training was arbitrarily performed for 100,000,000 frames, which took about 32 hours of runtime on a Titan X GPU.
Results
To get an idea of what the network is doing at every frame, we plotted the gameplay as well as the following information at every frame:
- Value
- Advantage for each of the 6 actions
- A running percentage of the actions taken by the modelH
- A handful of the activations at each of the layers in the convolutional network
Here’s a video showing an agent, which was trained for 15 hours, playing a game of Space Invaders:
Here are a few key takeaways from the visualizations:
- The value is a function of the amount of enemies on the map, the missiles fired by the avatar, and the location of the avatar. If the avatar moves beneath a shield, for example, the value decreases.
- Most actions constitute a move, a missile firing, or both. This means that the agent rarely spends any time simply waiting.
- Oftentimes the advantage of a certain action is only slightly higher than others. In the screenshot above, for example, the highest advantage is given to Move Left & Fire Missile. However, the constituent actions are also considered advantageous to the agent.
- The convolutional layers show glimpses into some of the features that the agent sees. Missiles being fired are visible as activated neurons, as are the enemy ships and the avatar itself.
It has been a fascinating and challenging project, and has been delightful to catch a glimpse of what is happening inside of the trained network. In the future we hope to continue training AI agents to play Atari games, as well as other benchmark simulations.
