2030年にはこうなっている、チャットボット先端開発事例

Incubit Blog Team
目次
「2030年には、ありとあらゆる分野でこれくらいのレベルのチャットボットが使える時代になっているのではないか」。
AI・人工知能EXPOに登壇した、国立研究開発法人 情報通信研究機構(NICT)の鳥澤健太郎氏は、そう言いながら次のような音声でのやり取りを紹介しました。
チャットボット「A銀行の定期預金が満期をむかえますね。B国の投資信託が人気のようですが、どうですか?」
ユーザー「でもB国の政権が不安定だから危ないんじゃない?」
チャットボット「そういう意見もありますが、一方で本日の新聞には面白いことが書かれていますよ。後で送ります」
いかがでしょう?事前に決められた対話ルールに沿うだけの現状のチャットボットと比べると、かなりインテリジェントな印象です。
「政治が不安定だと、普通は投資信託の価値が下がる」という事象を一般的な知識として持つことができている一方で、その内容と矛盾する「本日の新聞」の内容が「面白い」と判断することもできています。
また以下のやりとりのように、保有する知識をベースに、仮説や推論を行うこともできるようになると鳥澤氏はみています。
チャットボット「C社様向けの開発の件、Dアルゴリズムで効率化できそうです。関係する論文を送っておきます」
ユーザー「了解。開発チーム全員に送っておいて」
ユーザーが携わっている「C社様向けの開発」と「Dアルゴリズム」の内容をそれぞれ理解した上で、独立して存在している2つが関連しそうだという仮説を導きだすことができています。
「膨大なテキスト、つまりビッグデータを解析した上で多くの知識を持っていないと、このようなことはできない」と鳥澤氏は語ります。
次世代のボット開発に向けた取り組み
こうしたインテリジェントなチャットボットの実現に向けて、鳥澤氏らが開発したのが「WISDOMちゃん」という音声型チャットボット。
裏側のシステムには、すでに一般公開されているWisdom Xという大規模Web情報分析システムを採用しています。Web上にあがっている約40億ページ分の情報を知識として持ち、ユーザーの様々な質問に答えることができるといいます。
WISDOMちゃんはまだ着想してから約10カ月。当日公開されたデモでのやり取りは、とてもスムーズなものでした。
まだまだ研究開発の途上で、「頓珍漢な返事をすることもある」といいますが、より人間らしいやり取りの実現に向けて、従来のチャットボットとは異なる仕組みが導入されています。
より有益な会話の実現に向けた仕組みとは?
現状のチャットボットは対話のデータから学習することで、いわばそれを「マネすること」だと鳥澤氏はいいます。
「一時はみんながこの仕組みで挑戦したが、しばらく経つと悲鳴が聞こえてきた。何を言っても相槌しか打たない。これだけでは面白いことはできない」(鳥澤氏)。
つまりこういうことです。
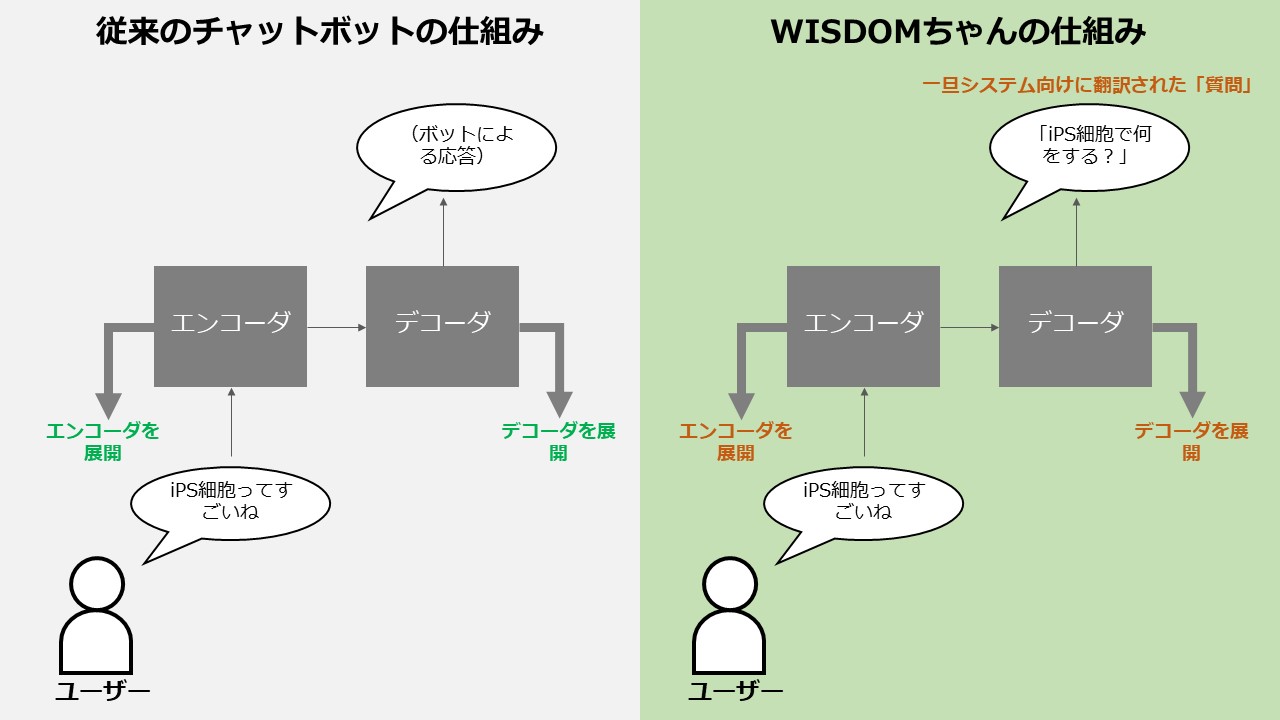
ユーザーとのやり取りの中には、たとえば「iPS細胞ってすごいね」といった意図が分かりにくい問いかけも多数。従来のボットでは、こうしたあいまいな問いかけの意図をうまく理解できず、単なる相槌や頓珍漢や返事に終始しがちでした。
そこで鳥澤氏らは、あいまいなユーザー入力が来た場合、まずそれをシステムが理解できる「質問」に翻訳することで、より自然な応答を返す仕組みを作りました。
たとえば以下がその一例です。
・ユーザー:「iPS細胞ってすごいね」
・Wisdom X:システム内部で「iPS細胞で何ができる?」という「質問」に変換
・Wisdom X:iPS細胞によって可能なことのリストの中から、面白そうな応答をピックアップして出力
「たとえばある端末や家電製品ってすごいよね、という発言があったとして、それに対して具体的に何ができるという返事が続くというのは、実際の対話でも割と自然な流れなのではないか」(鳥澤氏)。
多様な会話、「質問」の数を増やすことで実現
上記で育成した「質問」は、「iPS細胞で何ができるの?」というものでしたが、生成できる「質問」の種類が多ければ多いほど、様々な対話に対応できることになるというわけです。
たとえばユーザーからの問いかけとして、「日経新聞に『南鳥島沖に球状レアメタル』という記事が出ているね」というものがあったとします。
受験生向けの対話システムであれば、
・「質問」として「南鳥島はどこにある」を生成
・応答として「南鳥島は日本最東端にあります。覚えておきましょう」を返信
またビジネスマン向けの何らかのシステムであれば、
・「質問」として「レアメタルは何に使う?」「誰が(レアメタルを使う)ハイブリッド車を製造する?」を生成
・応答として「自動車会社に影響があるかもしれません」を返信
ただ育成した複数の「質問」の中から、適切な「質問」を選ぶという機能を実装するには、まだ至っていないとのこと。
今後の課題
こうした仕組みのチャットボットが目指す未来像は、ユーザーの目的を理解した上で、有益な雑談を行うというものですが、課題もあるといいます。
まず前提条件として、ユーザー自身やその目的に関する知識を大量に持たせる必要があるということ(適切なビッグデータの必要性)。
またそうしてユーザー特有の情報や状況に応じて返答をするということは、一種の疑似的な人格を持つ必要があるといいます。
たとえば一例として挙げられたのがドラえもん。「のび太を真人間にする」という目的を持ち、のび太に関する知識を山ほど持っていることで、例のドラえもんの「人格」が成立しているといいます。
そしてそのような疑似的な人格を、ビジネスや介護など様々な目的に応じて適切にプログラムすることは可能なのか?という点も懸念とのこと。
さらに大量の学習データの構築や、基礎的なテキスト解析の精度を向上させることも必須になってくるといいます。
ユーザーに寄り添うインテリジェントなチャットボットというのは、大きな可能性がありつつも、まだまだ課題も多そうです。