そもそもAIで何ができるのか?実現可能な7つの成果

Incubit Blog Team
目次
「AI(人工知能)を活用してビジネスで成果をあげよう」という動きがますます高まってきました。
しかし一方で「AIを魔法の杖だと誤解した人たちが、ムチャな要望を出してくる」というようなボヤキも、またよく耳にする話です。
つまりAI関連の技術によって、何ができて何ができないのか?という点があいまいなままに、期待だけが先行しがちというのが大方の現状といえそうです。
そんな中でちょっと便利な図をみつけました(記事最上部。オリジナルをもとにAI4U編集部で作成)。
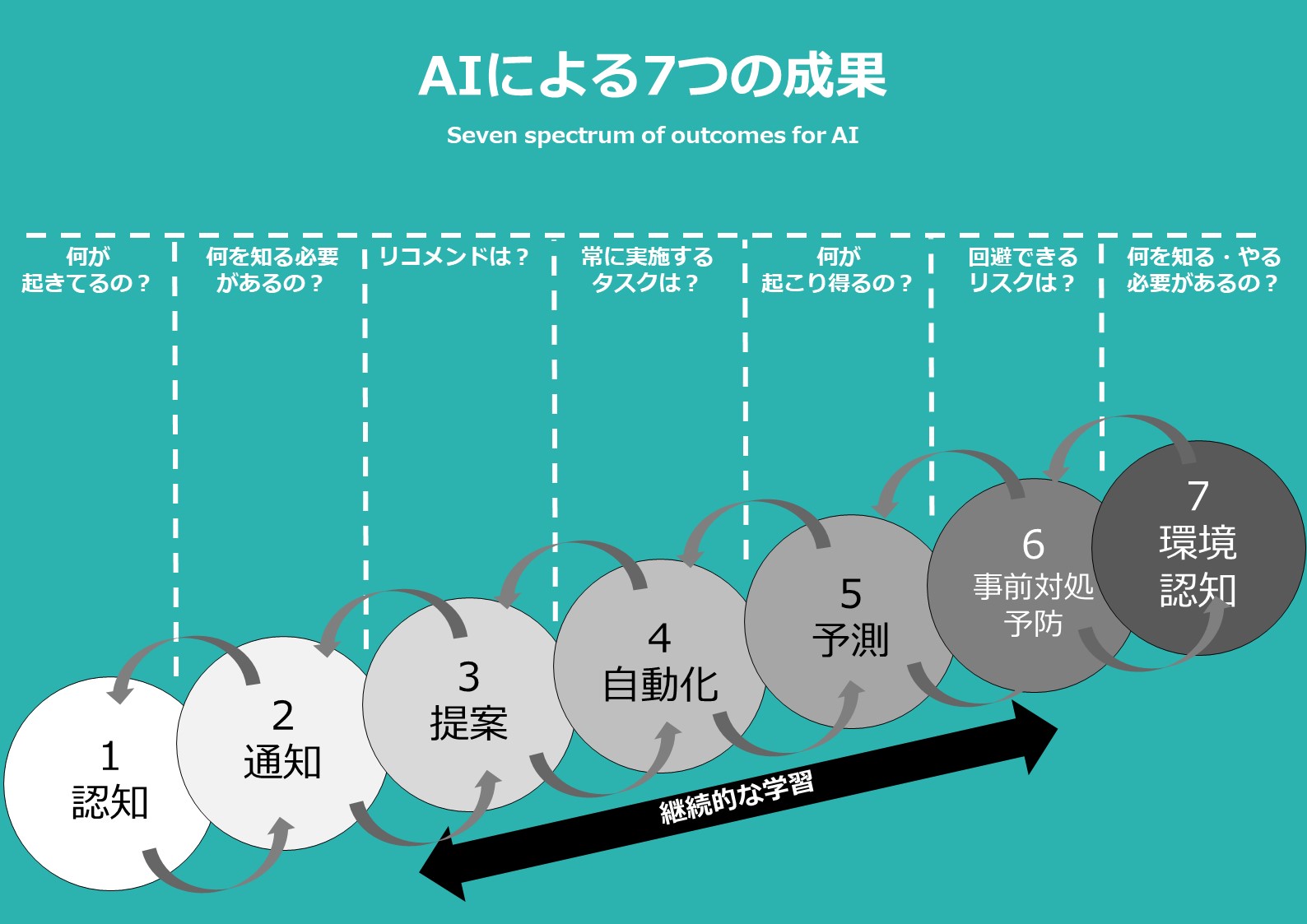
「AIによる7つの成果」(Seven spectrum of outcomes for AI)と題された図。その名の通り、AIによって解決できる成果、つまりユーザーニーズを7段階で整理しています。
「認知」や「通知」のように現時点の技術レベルで可能な段階もあれば、人の判断を手助けする「環境認知」といったまだ難しいレベルもあります。
AI事業を検討する際に、できることとできないことの整理に便利そうです。
それぞれの段階の説明はこちら。
1.認知
AIによって可能な項目の中で、最も初歩的な段階。画像や音声、感情といったデータをもとに、ユーザーに関する何らかのパターンを読み取る段階。
2.通知
ユーザーが知る必要がある情報をアラートやリマインダーといった形で通知。「適切な情報」を「適切なタイミング」で「適切なユーザー」に届けることで、唐突感なく自然に受け取ってもらうことを目指す。そのために必要なユーザーの属性や好みを把握するために地理データや天気、心拍数、感情など、あらゆるデータの活用を試みる。
3.提案・リコメンド
サイトのアクセスデータや商品の購買情報といった過去の行動データをもとに、ユーザーへのリコメンドを実施。そのリコメンド内容もマシーンラーニング(機械学習)などによって継続的に改善することができる。つまり少数ではなくマスのユーザー群に対して、コンテンツやマーケティング施策のパーソナライゼーションが可能になる段階。
4.自動化
ユーザーが抱えるタスクを自動で肩代わりできる段階。さらに機械学習によって継続的な改善やチューニングを実施できる。
5.予測
過去に蓄積されたデータをもとに、機械学習による予測ができる段階。
6.事前対処・予防
起こり得る問題を予測し、潜在的なリスクを回避できる段階。
7.環境認知
人がすべきことを判断する際の手助けができる段階。