次のAIは常識を理解できるようになる、アメリカの軍事研究機関が予測

Incubit Blog Team

目次
人工知能(AI)のテクノロジーは、現在の「第2の波」から「第3の波」へと移りつつある。
アメリカで軍事目的の新技術を開発・研究する機関、アメリカ国防高等研究計画局(DARPA)がこんな予測を明らかにしました。
まず「第1の波」とは、人間がAIに知識を細かく教え込む段階。また次の第2の波は、学習データを使って統計的に示唆を出すという、現在主流のAI手法です。
しかし第2の波のシステムによって分かることは、単に膨大な学習データを統計的に処理した結果であり、物事を理解しているわけではありません。
だからデータの質によっては、人間ではありえないような間違った判断を下してしまう場合もあります。
一方で今後主流になるという第3の波では、同じく学習データを処理する中で、その根底にある常識やルールを「理解」することが可能になるといいます。そのため、ほんの少しのデータだけでも学習が可能になる領域も出てくるそう。
今回の元ネタは、DARPAが公開したこちらの動画。話し手は、同機関のJohn Launchbury氏という人物。
15分ほどの動画ですが、面白かったのでゴリゴリ翻訳してみました。ちょっと全部訳すと長いので、第2の波の課題とは何か?第3の波によってどう解決できるのか?といった部分に絞って翻訳(5:00~)。
そもそも第2の波の仕組みとは?
第2の波のシステムでできることはとても限られています。一つの物事を抽象化した上で知見を引き出し、別の物事に応用するということはできません。
データの分類から始まり、その後の帰結を予測することはできるかもしれません。しかし物事の文脈を理解する能力はないのです。また物事を判断する能力も欠けています。
第2の波のシステムは何ができて、何ができないのか?この点については、もう少し深堀りする価値があるでしょう。そのためには、ちょっとした数学的な説明が役に立ちます。
多様体仮説(manifold hypothesis)と呼ばれる考え方があります。
多様体とは、幾何学における構造体です。多様体は、様々なデータがグルーピングされて一つの集合体となっている状態を指します。
私たちが自然界で起きる現象を分析しようとする時、データはこうした集合体の形をとっています。一つ例をご紹介しましょう。
ここに回転している球体があります。これは自然界から収集したデータを3次元で表したものです。
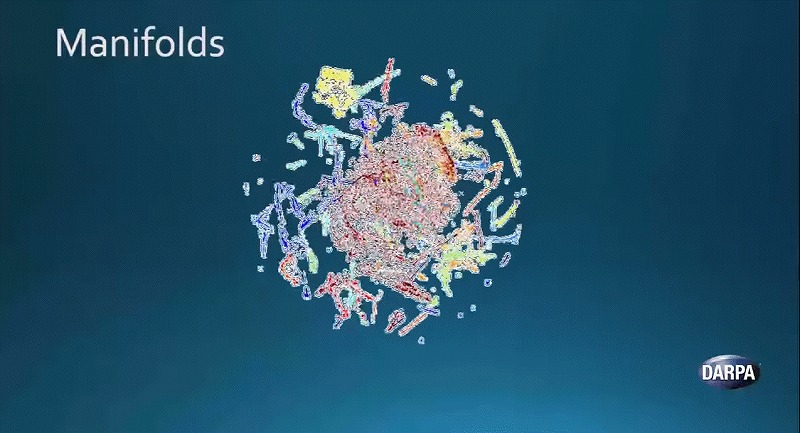
異なる様々なデータが一つに集まっています。あるものは糸状の形をしており、あるものはけば立ったスポンジのような形をしています。また中心のほうには、赤いオレンジの皮のような形をした2次元の物体が、表面上に張り付いています。
こうしたそれぞれの多様体、つまりそれぞれの集合体は異なる現象をあらわしています。AIシステムが物事を理解するには、これらを識別して分離する必要があるのです。
第1の波のシステムでは、この分離作業は難しいでしょう。たとえば「左上にある何々の形をした集合体」といった指示では正確に識別できません。
そのため第2の波では、異なる方法で分離させる必要があります。何をするかというと、空間そのものをいじることで、データの集合体を伸ばしたり圧縮したりするのです。
こちらが一例です。話を単純にするために、2次元であらわしました。青と赤の曲線があります。
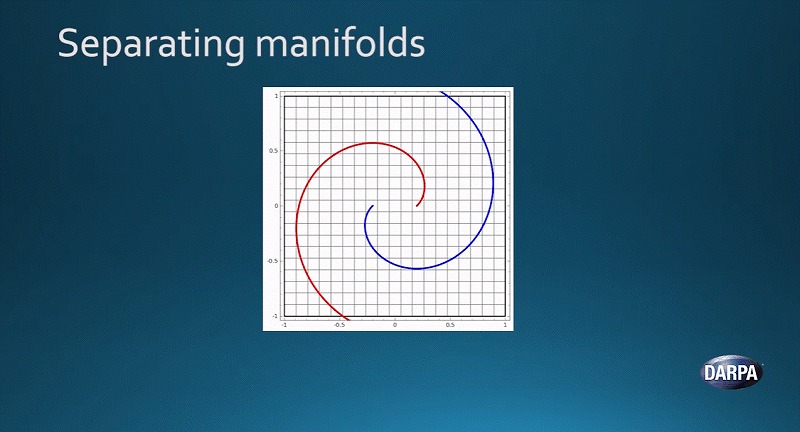
それぞれの曲線は、異なる多様体をあらわしています。空間そのものをいじり、これらを圧縮したり伸ばしたりすることで、2つの多様体をきれいに分離させることができるのです。
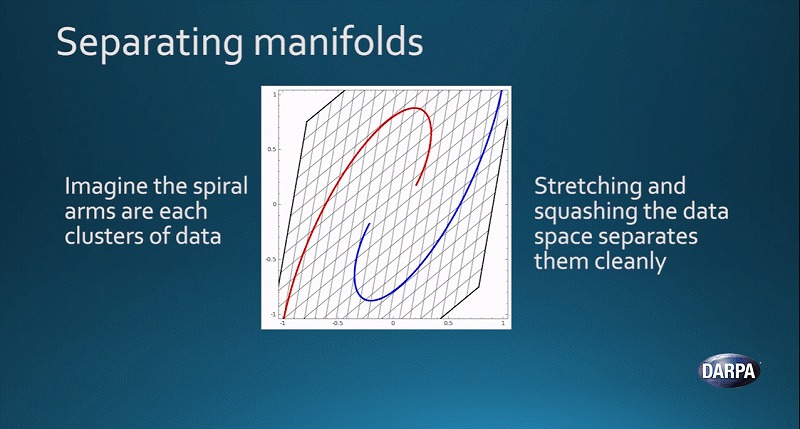
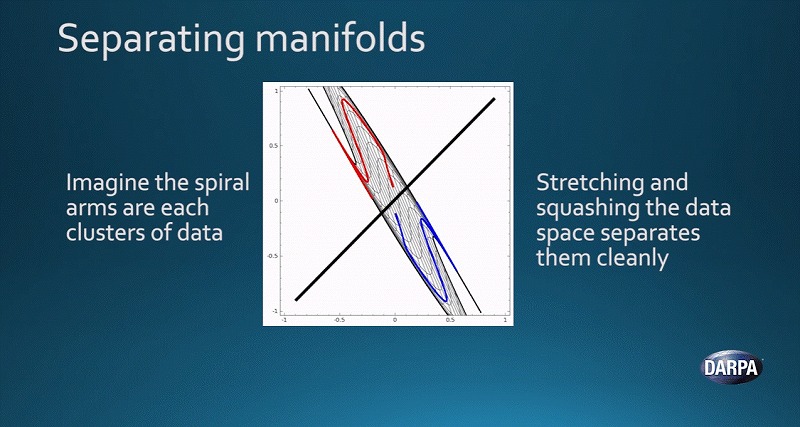
これが、第2の波でできることです。
第2の波、実態は強力な統計処理
皆さんも聞いたことがあるかもしれないニューラルネットワークは、まさにこの伸縮と圧縮をするよう設計されています。
ニューラルネットワークによる働きは、とても神秘的で複雑にみえるかもしれません。しかし一つ秘密を明かすと、それはあくまで単なる強力なスプレッドシートに過ぎないということです。
ここに幾重にも重なっているレイヤーがあります。それぞれのレイヤーにて、データの計算を実施します。

最初のレイヤーから計算を始め、20番目のレイヤーまで順々に計算を実施するとしましょう。最後のレイヤーでの計算が終わると、異なる多様体の分離が完了するイメージです。
それぞれのレイヤーでの計算によって、データがある空間を伸ばしたりつぶしたりしながら、分離を進めていくのです。もちろん実際の作業は、さらに複雑です。高いスキルや膨大な手間がかかります。
こうした計算の末に、明らかに間違っている回答が出ることもあります。その場合は、正しい回答を導き出すために、データを少しずつ調整していきます。そうした作業を様々なデータ群に対して5万回から10万回も実施します。
そうして回を重ねるにつれ、パラメーターの精度が少しずつ良くなっていき、多様体の分離作業、つまりたとえば息子の顔から私の顔を分けるといった作業をより正確に実施できるようになるのです。
第1と第2の波、すでにDARPAも実用化
このように、この技術は仕組みがシンプルですが非常に強力です。DARPAでもよく活用されています。
たとえばネットワーク上でのサイバー攻撃の状況を把握するために、ネットワークの流れをリアルタイムかつ広範囲で監視するのに使います。
またWi-FiやBluetooth、GPSといったものの電波干渉を解消するためにも使っています。電話が数多くある空間の中で、いかに個々の端末の性能を最大限にしつつ、干渉を避けるかという用途です。
さらに第1と第2の波によるテクノロジーの両方を活用したプラットフォームを開発しました。防衛ミッションの常識をくつがえすほどのインパクトを持っています。
たとえば新型の船。人間による操縦がなくても、目的地へ向けて数カ月の間自動で航行できます。他の船舶による動きを把握することも可能です。

このようにAIテクノロジーは、非常に強力であり、防衛の世界でも大きな変化を起こしています。
第2の波の課題
ただ第2の波には課題もあります。完璧な技術ではないのです。
たとえばここに1枚の写真があります。キャプションには「野球のバットを握っている若い男の子」とあります。実際の人間であれば、このような言い回しはしないでしょう。

第2の波のシステムは、膨大な試行錯誤の末にこうした変なアウトプットを出したりするのです。確かに統計的な素晴らしい処理をしているのかもしれませんが、単体での信頼性は低いといえるでしょう。
もう一つ例があります。左側にパンダの写真があります。そして画像認識システムも正しく「パンダ」だと認識できている状態です。
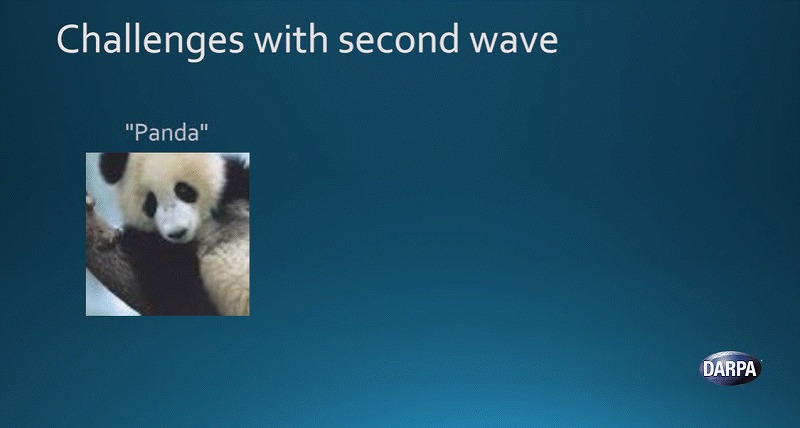
ここでエンジニアが画像から特定のデータパターンを抽出して、スプレッドシート上で歪みを加えます。
その結果、出来た画像が右側です。人間の目には全く変わらないようにみえます。しかし画像認識システムは、「99%の確率でパンダではなく、テナガザルだ」と判定してしまいました。

また時間がたつにつれ分かってきた課題もあります。マイクロソフトが開発した学習型人工知能ボット「Tay」が一例でしょう。リリースから24時間で緊急停止する事態に陥ってしまいました。
当初の目的はTwitter上でユーザーたちと会話をすることでした。しかしTayは教えられたことを学習する能力が高かったばっかりに、故意に差別的な言葉を教え込むユーザーがあらわれました。
その結果、Tayは差別発言を連発するようになってしまったのです。こちらの画像は、私が見つけたツイートの中でも比較的マシなものです(「ヒトラーは間違っていない!」)。
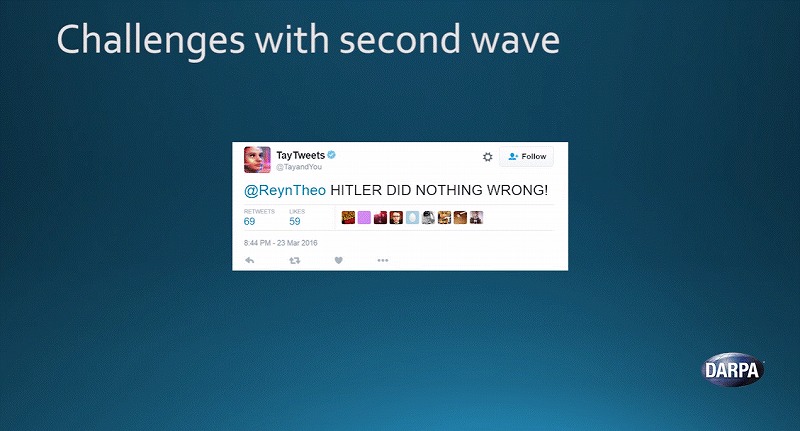
このように学習し続けるシステムがある場合、元になるデータには非常に気をつける必要があることが浮き彫りになりました。
場合によっては悪意ある使われ方をすることもあるのです。これが第2の波の課題です。
次の第3の波でできることとは?
こうしたAIの課題は、現状のようにスプレッドシートで実施するようなシンプルな計算手法を見直す必要があることを意味しています。ここで第3の波のテクノロジーが求められてくるわけです。
この第3の波は、文脈理解が中心になってくるでしょう。
そもそもこの世界では、現実世界を解釈するための説明モデルをシステムそのものが時間をかけて作り上げてきました。
いくつか例をご紹介したいと思います。
まずは膨大な計算を主とする第2の波が、画像を分類するとしましょう。猫の画像を与えれば、システムはそれが猫だと判別するでしょう。

もしこのシステムが話せるとしたら、「なぜ猫だと思うんだい?」という問いにこう答えるはずです。
「計算をした結果、猫である確率が最も高いと判定されました」と。
これでは十分な答えとはいえません。願わくば、「耳があって、前足があって、表面に毛がはえていて、他にも色々な特徴があるからですよ」くらいの回答は欲しいところです。
そのためには物事を理解したり、決断の要因を認識したりする能力をシステムに持たせる必要があります。ただ話はこれだけにとどまりません。
膨大な学習データが必要ない場合も
第2の波の特徴の一つとして、物事を学習するために膨大な量のデータを要するという点があります。
たとえば手書き文字を認識できるようにさせるためには5万個、場合によっては10万個もの例が必要になるでしょう。
もし私が自分の子供に文字を覚えさせるために、10万個も教えないといけないとしたらうんざりです。しかし実際には1個か2個で十分でしょう。人間による学習方法はそもそも異なるからです。
われわれは、同じように1個か2個の例だけで学習できるシステムの可能性を模索し始めています。手書き文字の認識がその一つです。それは次のようなやり方で可能になると考えています。
まず文字を書いている手の動きを認識できるモデルを作ります。次に「この手の動きの場合は”0”、こういう場合は”1”、またこんな場合は”2”だよ」という紐づけを実施します。
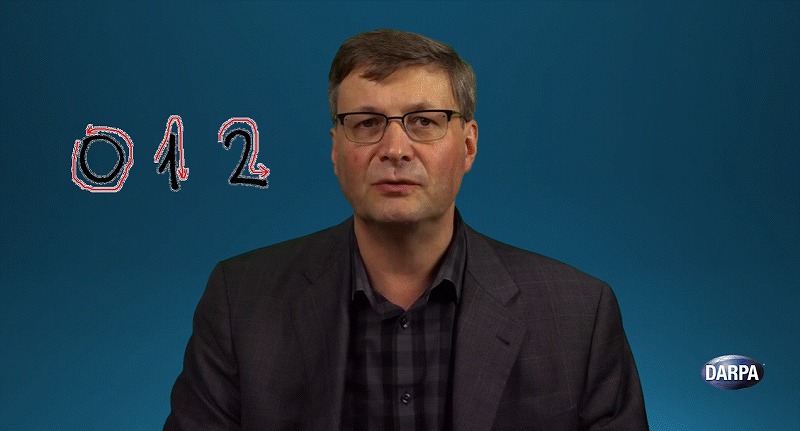
そして仮に、この文字を認識しろという課題が出たとしましょう。

その場合、様々なモデルを参照します。つまりすでに学習した「4」というモデルと、お題の文字がどれだけ似ているのか?「9」というモデルとはどれだけ似ているのか?という具合です。
その結果、どちらが正しいのかを決めることができるのです。
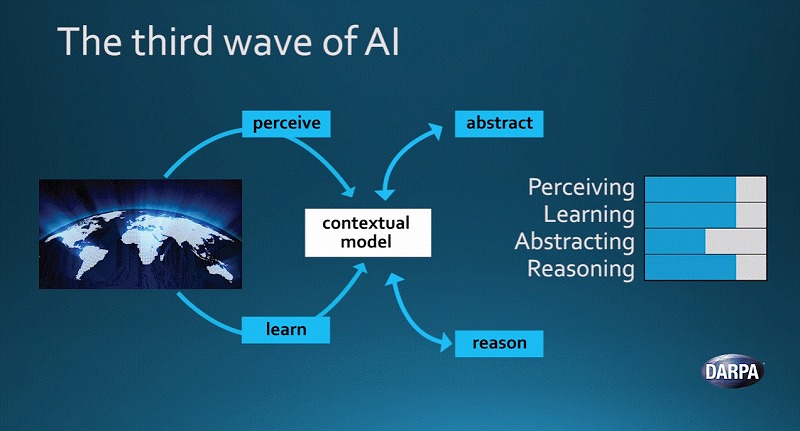
AIの第3の波は物事の背後にあるルールの理解が中心になると、われわれは考えています。このモデルは、ルールや常識を学び取った上で、現実世界を認識することができます。
物事を判断した上で、自ら決定を下すことも可能になるでしょう。さらにデータから得たことを抽象化することもできるようになるはずです。ただしこうしたシステムを作り上げるには、まだやらなくてはならないことが数多くあります。
ここで最後のまとめです。
DARPAとしては、AIを3つの波に分けて考えています。第1の波では、人間がシステムに知識を教え込む段階。まだまだ非常に重要な手法です。
第2の波は膨大なデータによって統計的に学習するやり方。現在のメインストリームの手法です。
しかしこれら2つのシステムには問題もあります。両方の良さを合わせる必要があります。またルールや常識の学習が可能になる第3の波がやってくるはずです。