自動運転にも応用される精緻な画像認識技術、「画像セグメンテーション」とは?事例を交えてわかりやすく解説

Incubit Blog Team

目次
近年、ディープラーニング(深層学習)を中心とした機械学習の技術が注目を集めています。そのホットな応用先の1つが画像認識です。
今回は「画像×機械学習」によって、精緻な画像識別を可能にする技術、”画像セグメンテーション”について見ていきましょう。
画像分類の種類について
「画像×機械学習」といってもその応用例はたくさんあります。
画像セグメンテーションの特徴を理解するためにも、まずはよく使われているその他の画像分類技術も見ていきましょう。
今回は画像セグメンテーションを含む、こちらの3つを紹介します。
1)画像分類(classification)…”その画像が何なのか”を識別
2)画像検出(detection)…”その画像のどこに何があるのか”を識別
3)画像セグメンテーション(segmentation)…”その画像領域の意味”を識別
1)画像分類(classiification)…”その画像が何なのか”を識別
画像分類では、”その画像が何なのか”カテゴリ分けします。
例えば、様々な寿司ネタの書かれた画像を「これはサーモン、これはいくら、これはとろ、、、」というように一枚一枚分類していく感じになります。
最近AmazonからリリースされたAmazon RekognitionのObject and scene detectionもこの画像分類にあたりますね。
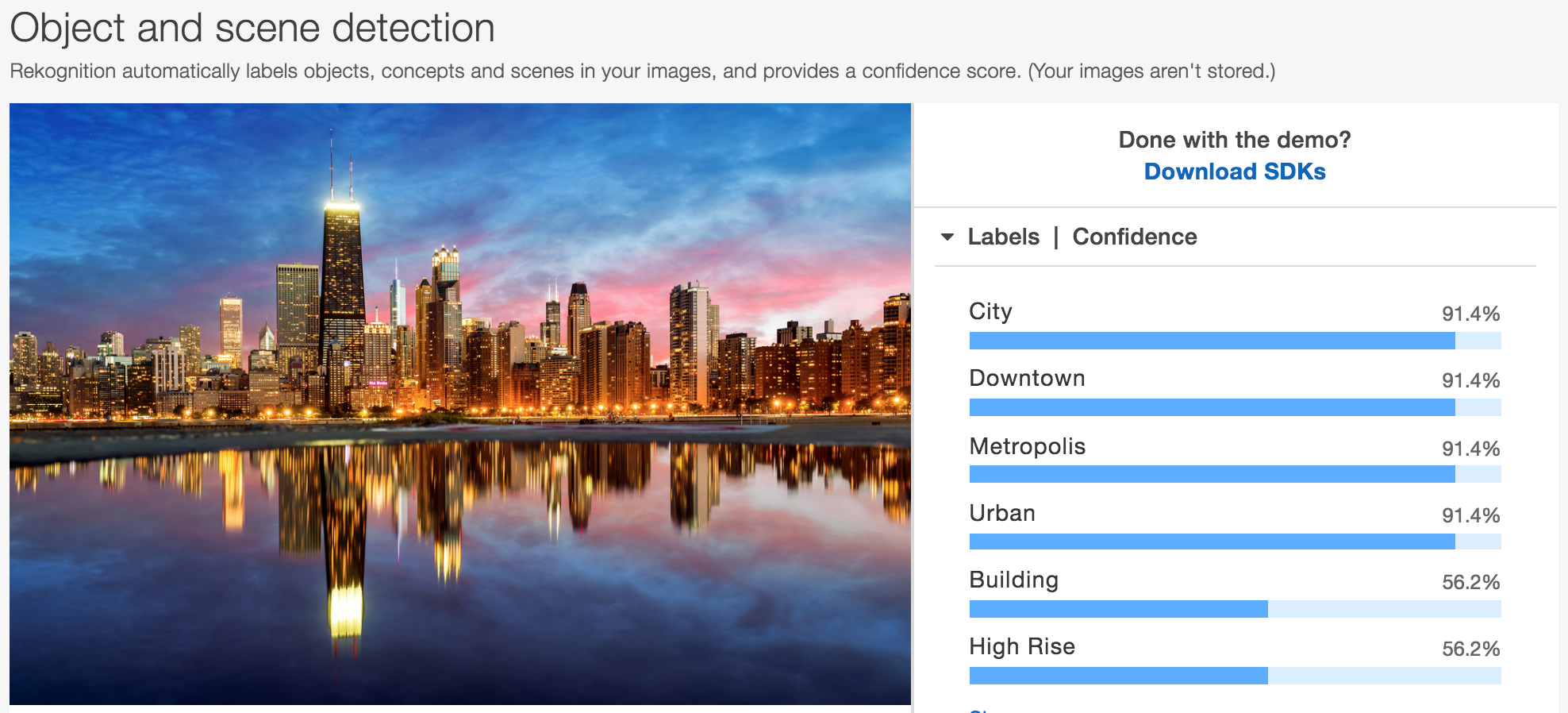
こちらの画像では、対象の画像がCityやDowntown、Metropolisであると分類されています。
この方法では1枚の画像が1つの物体等を映し出していた場合には有効ですが、複数の対象が写っていた場合、それぞれを認識することはできません。
例えば、今机にある複数の物体を写真に撮ってRekognitionにアップロードしてみます。
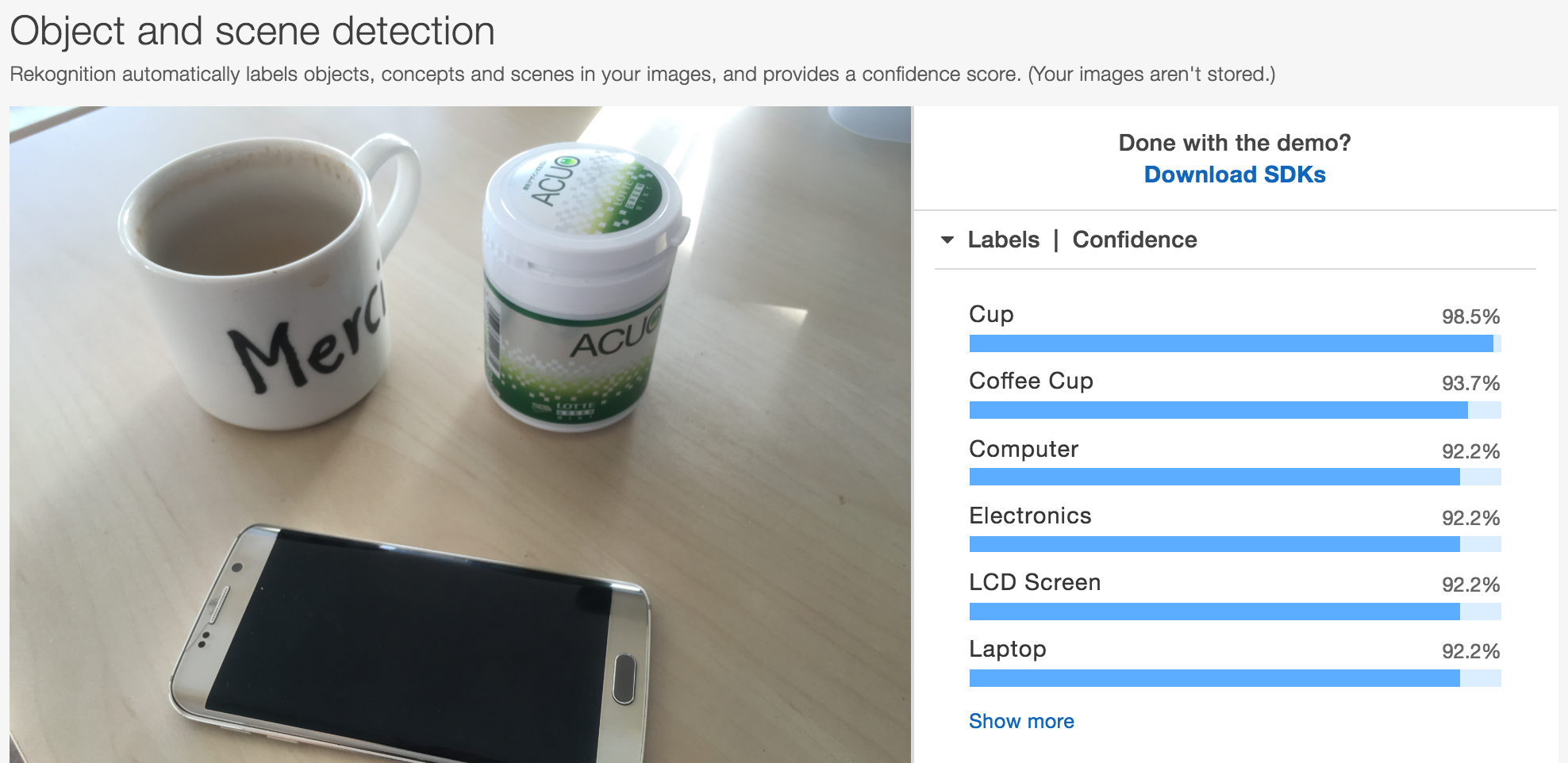
本来であれば「カップとスマホとボトル」が写っているのですが、Amazon Rekognitionでは画像全体へのラベル付けとしてCupやCoffee Cupが上位に来ています。
これでは、複数の物体が画像に入り込むシーンでは使えないですね。そういった場合には「画像検出(detection)」を活用することになります。
2)画像検出(detection)…”その画像のどこに何があるのか”を識別
detectionと呼ばれる画像検出では、“何があるのか”に加え“どこにあるのか”も識別ができます。
例えば、先程の画像を例にとると、以下のように「コーヒー、ボトル、スマホ」という3つのwhatとwhereが識別できます。

Facebook上に写真をアップロードすると、顔の部分をタグ付けできるようになっていますが、あの技術も顔を検出する画像検出が使われている例ですね。
Amazon RekognitionにもFace Analysisの機能があったのでこちらの画像も例として載せておきます。
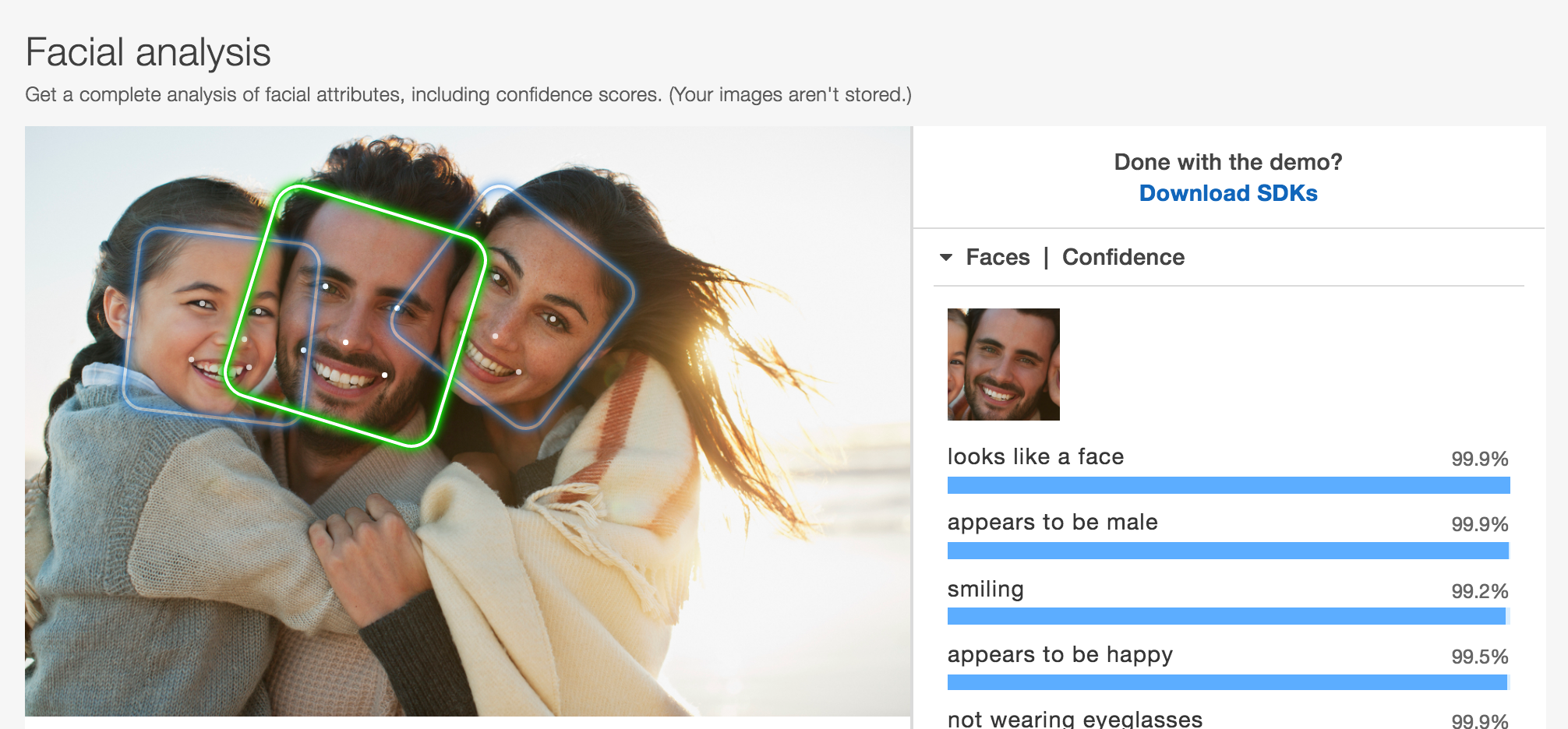
この画像のように、”顔がどこにあるのか?”が顔認識では取得できています。
3)画像セグメンテーション(segmentation)…”その画像領域の意味”を識別
それでは今回のメインである画像セグメンテーションについて見ていきましょう。
Semantic Segmentation と呼ばれる画像セグメンテーションでは、画像全体や画像の一部の検出ではなくピクセル1つひとつに対して、そのピクセルが示す意味をラベル付けしていきます。
画像を見たほうがわかりやすいので実際の画像を見てみましょう。

引用:http://jamie.shotton.org/work/research.html
一番左の画像では、”牛(cow)”に加え“草(grass)”も色づけされています。
これまでに紹介した画像検出では牛という物体が4体検出される以上のことはできませんでしたが、Semantic Segmentationでは画像全体がピクセルごとに意味づけされます。
この技術の応用例の1つ、自動車の自動運転があります。自動運転では以下のようにリアルタイムでセグメンテーションが行われます。
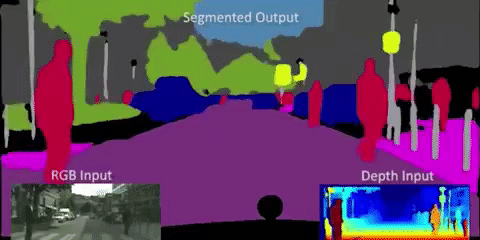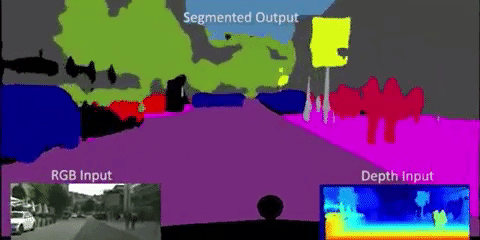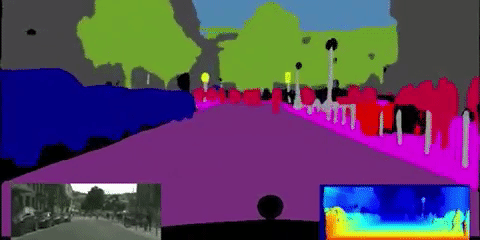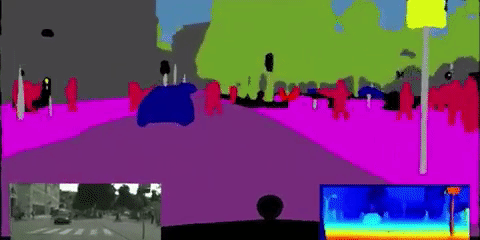
引用:http://worldwide.chat/E6gij6IS8n0.video
ファッション領域で画像セグメンテーションを使ってみる。
それでは画像セグメンテーションの精度をみるために、実際に人間が着ている服装をsemantic segmentationで識別してみましょう。ここから少し技術的な話になります。
○アルゴリズム
今回はFully Convolutional Neural Networkを使いSemantic Segmentationを行います。
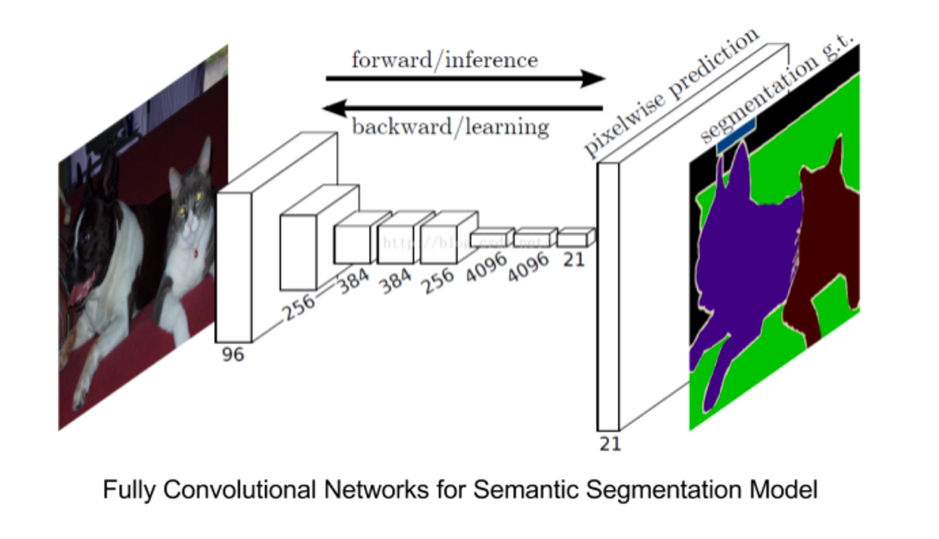
引用:https://arxiv.org/abs/1411.4038
○データセット
こちらのデータセットを拝借しました。
https://sites.google.com/site/fashionparsing/dataset
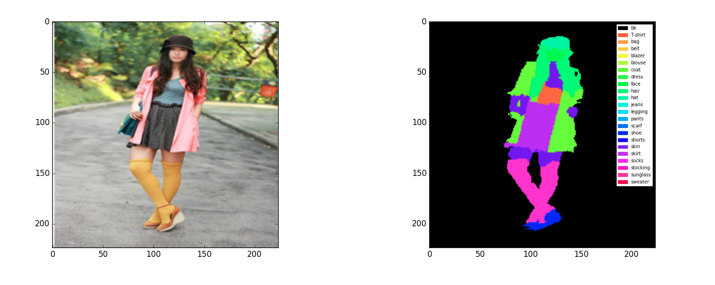
こちらのデータ・セットでは、左図のような通常の写真と右図のようなピクセルごとに色付けされた画像のセットが2683組あり、「背景」「Tシャツ」「カバン」「ベルト」「ブレザー」「ブラウス」「コード」「ドレス」「顔」「髪」「帽子」「ジーンズ」「レギンス」「パンツ」「スカーフ」「靴」「シャツ」「肌」「スカート」「靴下」「ストッキング」「サングラス」「セーター」という領域に分けて色付けがされています。
○学習
今回は私たちインキュビット社にあるNvidia GPU TitanXのマシンを使ってTensorFlowで実装を行い、データのうち90%を学習に10%を検証に使いました。
Adam optimizerのモデルを使い、バッチサイズ:50、学習率:10^-5、ドロップ率:0.5をという条件で約10時間かかっています。
○結果

セグメンテーションの精度はまぁまぁなようですが、すこし色が違う部分が有りますね。ブラウスやブレザー、ジーンズやレギンス等、細かな部分を識別しきれていないようです。人間がみても見分けづらい箇所なので、難易度は高いのでしょう。
データセットが100万組ほどあるとジーンズとレギンスといった細かい違いにも対応できるかと思います。しかし今回は2700枚以下のセットしかないので、以下のようにも少し大雑把でシンプルな分類にしてみましょう。
・Tシャツ、かばん、ブレザー、ブラウス、コート、セーター → トップス
・顔、帽子、サングラス → 顔
・ジーンズ、レギンス、パンツ、ショートスカート → ボトム
・靴下、ストッキング → 靴下

今度はかなり正答例と近くなりましたね。
画像セグメンテーションではこのような感じで、学習データを用意しモデルを作成していきます。
■最後に
今回の記事では
・「画像×機械学習」の応用として、画像分類、画像検出、画像セグメンテーションを紹介しました。
・画像セグメンテーションの例として、服装のセグメントのステップを実際のデータを用いてご紹介しました。
Incubitでは、ディープラーニングを用いた画像認識エンジンをオーダーメイドで開発しています。
詳しくは、お問い合わせページよりお気軽にお問い合わせください。